10 Data Engineering Tools You Need to Know in 2023

Data engineering has become increasingly important in recent years as companies continue to produce more data than ever before. With this influx of data, businesses need to be able to manage, process, and analyze it in a way that makes sense. In order to do this, they need to rely on data engineering tools that can help them get the most out of their data.
In this article, we will take a look at the top 10 data engineering tools you need to know in 2023. We will discuss traditional tools that have been around for a while, as well as newer tools that are gaining popularity. We will also explore cloud-based tools that are becoming more prevalent as more and more companies move their data to the cloud.
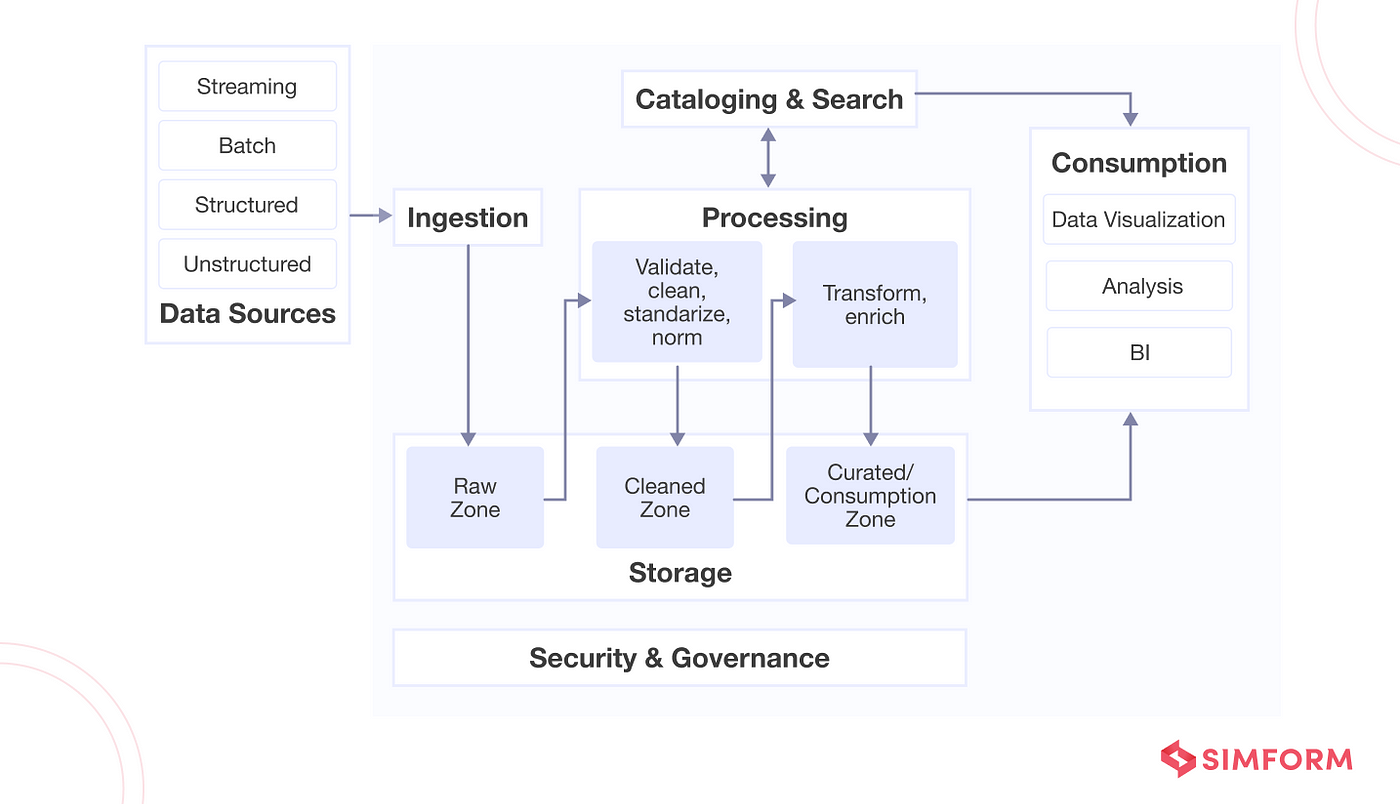
Traditional Data Engineering Tools:
Traditional data engineering tools have been in use for several years and are still widely used today. Some of the most popular traditional data engineering tools include:
- SQL: Structured Query Language (SQL) is a standard language for managing relational databases. SQL is used to create, modify, and manage databases, tables, and data. One of the advantages of SQL is that it is a declarative language, which means you don’t need to worry about how the query is executed. The disadvantage of SQL is that it is not suitable for handling unstructured data.
- ETL: Extract, Transform, Load (ETL) is a process that involves extracting data from different sources, transforming it into a common format, and then loading it into a target database or data warehouse. ETL tools help to automate this process, saving time and effort. The disadvantage of ETL is that it can be slow and complex.
- Hadoop: Apache Hadoop is an open-source framework for storing and processing large datasets. Hadoop is widely used for big data processing and can handle structured, semi-structured, and unstructured data. One of the advantages of Hadoop is that it is scalable and can handle petabytes of data. The disadvantage of Hadoop is that it can be complex to set up and manage.
Emerging Data Engineering Tools
Emerging data engineering tools are gaining popularity due to their ability to handle big data and unstructured data. Some of the most popular emerging data engineering tools include:
4. Spark: Apache Spark is an open-source big data processing framework that can handle both batch and streaming data. Spark is known for its speed and efficiency and can handle complex algorithms and machine learning models. One of the advantages of Spark is that it can handle both structured and unstructured data. The disadvantage of Spark is that it can be complex to set up and manage.
5. Kafka: Apache Kafka is an open-source distributed event streaming platform that can handle real-time data feeds. Kafka is known for its speed and efficiency and can handle large volumes of data. One of the advantages of Kafka is that it can handle both structured and unstructured data. The disadvantage of Kafka is that it can be complex to set up and manage.
6. Flink: Apache Flink is an open-source stream processing framework that can handle both batch and streaming data. Flink is known for its speed and efficiency and can handle complex algorithms and machine learning models. One of the advantages of Flink is that it can handle both structured and unstructured data. The disadvantage of Flink is that it can be complex to set up and manage.
Cloud-Based Data Engineering Tools:
Cloud-based data engineering tools have been gaining popularity in recent years as they offer numerous advantages over traditional on-premises solutions. These tools can help streamline the data engineering process, reduce costs, and provide scalability and flexibility to handle large volumes of data.
Cloud-based data engineering tools include services such as AWS Glue, Google Cloud Dataflow, Azure Data Factory, and Snowflake. These services provide a variety of features such as data integration, data transformation, and data pipeline management.
7. AWS Glue: AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to move data between data stores. With AWS Glue, users can create and run ETL jobs that extract data from a variety of sources, transform it, and load it into various target data stores.
AWS Glue provides a number of features including automatic schema discovery, data cataloging, and data lineage tracking. It also integrates with other AWS services such as Amazon S3, Amazon RDS, and Amazon Redshift.
8. Google Cloud Dataflow: Google Cloud Dataflow is a fully managed service for developing and executing data processing pipelines. With Dataflow, users can build and execute batch and streaming data pipelines using popular programming languages such as Java, Python, and Go.
Dataflow provides a number of features including automatic scaling, data windowing, and watermarking. It also integrates with other Google Cloud services such as BigQuery, Cloud Storage, and Pub/Sub.
9. Azure Data Factory: Azure Data Factory is a fully managed data integration service that enables users to create, schedule, and orchestrate ETL/ELT workflows. With Data Factory, users can extract data from various sources, transform it, and load it into various target data stores.
Data Factory provides a number of features including data movement, data transformation, and data pipeline management. It also integrates with other Azure services such as Azure Blob Storage, Azure SQL Database, and Azure Synapse Analytics.
10. Snowflake: Snowflake is a cloud-based data warehousing platform that provides a fully managed and scalable solution for storing and analyzing large volumes of data. With Snowflake, users can store and query structured and semi-structured data using SQL.
Snowflake provides a number of features including automatic scaling, data sharing, and data encryption. It also integrates with other cloud services such as AWS, Google Cloud, and Azure.
Conclusion:
Cloud-based data engineering tools offer numerous advantages over traditional on-premises solutions. They provide scalability, flexibility, and cost savings that can help organizations handle large volumes of data more efficiently.
AWS Glue, Google Cloud Dataflow, Azure Data Factory, and Snowflake are just a few examples of the many cloud-based data engineering tools available today. Choosing the right tool depends on the specific needs and requirements of each organization.